revRSS: The basic infrastructure behind finding reverse split press releases and trading on them
Note: Though this article mentions the idea of trading on reverse splits, the idea is given not for any compensation and not as personal financial advice for the reader’s specific financial situation.
A couple of years ago, I used to be subscribed to a mailing list called “Reverse Split Arbitrage”, and I remember being surprised that the trading tips that landed in my mailbox did make me a bit of money. The central idea of it was based on a kind of stock market technicality.
When a company executes a “reverse split”, it takes every X shares and merges them into a single share, thereby raising the price because the value of the company is divided among fewer shares. “X” is a number that comes from the announced ratio “1-for-X”. (This language is similar to the “X-for-1” ratio of stock splits, or in other words forward splits, though in that case the value is divided among more shares to lower the price.) Reverse splits typically happen because the price has fallen under $1, the minimum price set by the NYSE and Nasdaq to stay listed.
But here’s the big-money question: what if an investor has less than X shares left over? Under the given ratio, that would have to become a so-called “fractional share”. Companies typically take one of four approaches to this fraction:
- pay cash for this fraction,
- round it down to zero or one, whichever is nearer,
- round it down to zero unconditionally, but most commonly,
- round it up to one unconditionally.
Which option the company takes can almost always be found in the press release or SEC filing that is published shortly before the reverse split happens. These emails I had gotten from Reverse Split Arbitrage would alert me to these reverse splits that would round up, but after some time, I wasn’t getting them anymore.
Still, it turns out that plenty of reverse splits are still happening, and many of them are still rounding up. I wanted to get back into trading on them, but I didn’t have the mailing list to help me any more. I had to rig up something myself, of course! This was also something I wanted to share with others—for zero compensation especially. For now, I’m doing a soft launch of this at www.revrss.com, and it’s in a limited form that focuses only on press releases (not SEC filings) and requires the reader to read them themselves. The intention is to make it more public after overcoming these limitations, but I’ve been able to use it myself just fine.
With that said, even getting this far required quite a bit of infrastructure! If I were to describe what I’m doing in one phrase, referring to the technologies involved just by their name, it would be “a WebSub-enabled RSS news aggregator, served via nginx over Cloudflare Tunnels”.
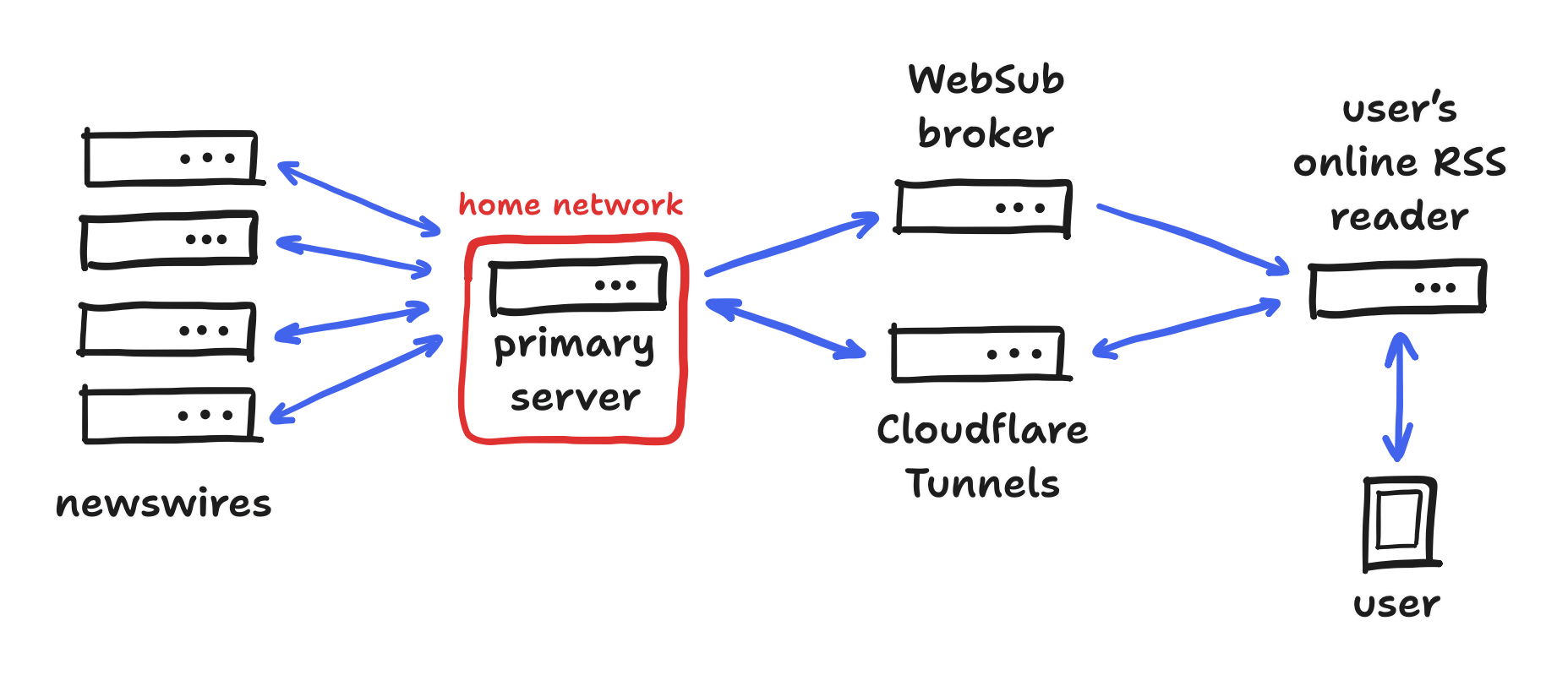
And now, I’ll say it again in longform.
Press releases about reverse splits (and whether they’ll round up) happen to be distributed by one of four newswires, Business Wire, PR Newswire, ACCESSWIRE, and Globe Newswire, though they may also be sent out via smaller newswires like Newsfile Corp, EIN Presswire, or Dow Jones Newswire. The first four are used dramatically more than the latter three.
Though newswires usually forward their news directly to their journalist clients, they also share it directly with the public via one channel or another. If a newswire made their news available in RSS, the standard format for distributing news from machine to machine, then I had written a program for interpreting that. (In the case of PR Newswire, I managed to talk to someone there about getting an RSS feed!) If they instead made it available via their website, then I had to resort to “web scraping”, in other words parsing the HTML code meant for web browsers.
Naturally, if a newswire offered RSS, I went for it over going to their website. In either case, though, I could use a Python library for parsing XML and HTML data, called Beautiful Soup, to do the heavy lifting. In general, both XML and HTML organize data into “tags”—“tags” being containers of many blocks of text, sub-tags, or even both at the same time. In the case of RSS, which is a kind of XML, the way a news article and its associated metadata is encoded with these tags is exactly defined in the RSS specification, and so the specification was a good reference in instructing Beautiful Soup to find the tags associated with said article. In the case of HTML though, an article ends up being encoded in ways varying from website to website, and so I ended up needing to pick through each website by hand to find the tags to give to Beautiful Soup.
Still, with effort, I could have myself a list of articles from all of the relevant newswires—each article with its title, link, published date, and excerpt. I just needed to filter it for press releases about reverse splits and then sort by latest. With that said, a dire wish of mine here is to achieve a better filter here. Because the language that declares a reverse split with round-ups varies, identifying such without making many false positives or false negatives would require good natural language processing. For now, I’m leaning toward more false positives, selecting only for reverse splits but not whether they’ll round up. That can be done with a simple keyword search. With this (admittedly faultily) filtered list, then sorted by latest, I could even begin to report something to the public.
My choice for how I did this was RSS again, not a full website nor a mailing list. With that said, serving RSS is not like the latter and much like the former. To be exact here, the relationship is identical to serving a “static website”, or in other words a website built on a set of fixed assets, including HTML, CSS, images, or even Javascript but not including responses of a database. As mentioned here, RSS is just a format, and so an RSS service is just a single file, served as if it were a logo on some corporate website. Consequently, I could construct this file using Beautiful Soup and then serve it using a configuration of the nginx program, which was designed for such static assets.
Speaking of static websites, I configured nginx to also serve the revRSS website (just a for-your-information site) which was a static website. For that, “static site generator” programs like Jekyll can autogenerate all the assets of a static website from plaintext files and configuration files (which can come from publicly available templates like Beautiful Jekyll). I think detailing how using Jekyll went for me is outside the scope of this article, but I mention this because I want to highlight how serving the site and serving the reverse splits feed are completely equivalent. In fact, the same nginx configuration serves both.
Anyway, a key disadvantage of RSS from mailing lists is that notifications are impossible because there is no list of subscribers to contact. This wouldn’t be a problem if—say—one made a habit of checking the feed every morning, but I don’t think that should be necessary. So, since I wanted to serve RSS but also deliver notifications, what was I to do? The answer was to use another program on the side that follows the WebSub (formerly PubSubHubbub) protocol. This other program maintains the list, and some apps like NewsBlur are capable of joining that list. It could be run on the same server that runs nginx, but I used a public “broker”. In particular, I used the one run by Google at pubsubhubbub.appspot.com.
Finally, I wanted to host everything on a powerful server at home, but my internet provider doesn’t allow me to open the standard ports for HTTP and HTTPS, 80 and 443. By “opening” ports, I mean accepting incoming connections there. Though opening other ports and manually punching in the port numbers may technically work for me, that wouldn’t work for the public. One solution for this I’ve done before is a reverse SSH tunnel, a type of SSH connection that one server makes to another server in order for the latter to act as a face of the former, accepting connections at its own ports for the former. In this scenario, a connection would be issued by my server (not accepted) and from there traffic is forwarded back, and this would get around my internet provider’s restriction. To do this, the other server could just be rented from a cloud provider like Google Cloud—possibly while staying within the limits of their free tier.
However, I went for something similar using Cloudflare Tunnels instead. The tradeoff: I don’t have to manage two servers, but I lose control of the other end to Cloudflare. With that said, I planned to proxy my traffic through them anyway because I wanted to use their content delivery network to serve the heaviest parts of the revRSS site for me, including fonts and images. To me, their Tunnels feature was icing on the cake.
So, that’s how I’m getting and trading on the latest press releases about potential reverse split round-ups as they happen. With this infrastructure, it’s also how—technically—you can too. It’s a basic infrastructure that actually needs to become more complex before it’s something I could count on more simply, really, and yet it invokes a wide range of concepts already. From file formats to servers to tunnels, each has a different role in transporting the news of a reverse split from the company to my phone.
I could end up adding more to this pipeline, and if I write a piece on it, you can click to it here.